Processing Events¶
Most applications have a definite state - they remember past user input and interactions. It is advantageous to model these past changes as a series of discrete events. Domain events happen to be those activities that domain experts care about and represent what happened as-is.
Domain events are the primary building blocks of a domain in Protean. They perform two major functions:
- They facilitate eventual consistency in the same bounded context or across.
This makes it possible to define invariant rules across Aggregates. Every change to the system touches one and only one Aggregate, and other state changes are performed in separate transactions.
Such a design eliminates the need for two-phase commits (global transactions) across bounded contexts, optimizing performance at the level of each transaction.
- Events also keep boundaries clear and distinct among bounded contexts.
Each domain is modeled in the architecture pattern that is appropriate for its use case. Events propagate information across bounded contexts, thus helping to sync changes throughout the application domain.
Defining Domain Events¶
A Domain event is defined with the event() decorator:
@domain.event(aggregate_cls='Role')
class UserRegistered:
name = String(max_length=15, required=True)
email = String(required=True)
timezone = String()
Often, a Domain event will contain values and identifiers to answer questions about the activity that initiated the event. These values, such as who, what, when, why, where, and how much, represent the state when the event happened.
Since Events are essentially Data Transfer Objects (DTOs), they can only hold simple field structures. You cannot define them to have associations or value objects.
Ideally, the Event only contains values that are directly relevant to that Event. A receiver that needs more information should listen to pertinent other Events and keep its own state to make decisions later. The receiver shouldn’t query the current state of the sender, as the state of the sender might already be different from the state it had when it emitted the Event.
Because we observe Domain Events from the outside after they have happened, we should name them in the past tense. So “StockDepleted “is a better choice than the imperative “DepleteStock “as an event name.
Raising Events¶
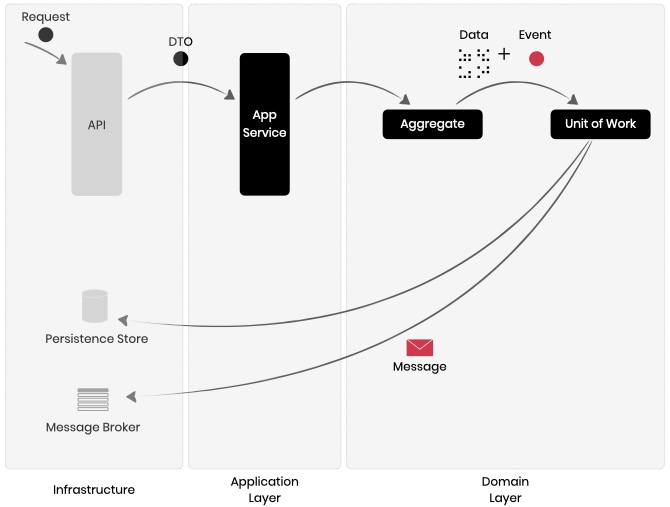
Domain events are best bubbled up from within Aggregates responding to the activity.
In the example below, the Role aggregate raises a RoleAdded event when a new role is added to the system.
...
@domain.aggregate
class Role:
name = String(max_length=15, required=True)
created_on = DateTime(default=datetime.today())
@classmethod
def add_new_role(cls, params):
"""Factory method to add a new Role to the system"""
new_role = Role(name=params['name'])
current_domain.publish(RoleAdded(role_name=new_role.name, added_on=new_role.created_on))
return new_role
Adding a new role generates a RoleAdded event:
>>> role = Role.add_new_role({'name': 'ADMIN'})
>>> role.events
[RoleAdded]
UnitOfWork Schematics¶
Events raised in the Domain Model should be exposed only after the changes are recorded. This way, if the changes are not persisted for some reason, like a technical fault in the database infrastructure, events are not accidentally published to the external world.
In Protean, domain changes being performed in the Application layer, within Application Services, Command Handlers, and Subscribers for example, are always bound within a UnitOfWork. Events are exposed to the external world only after all changes have been committed to the persistent store atomically.
This is still a two-phase commit and is prone to errors. For example, the database transaction may be committed, but the system may fail to dispatch the events to the message broker because of technical issues. Protean supports advanced strategies that help maintain data and event sanctity to avoid these issues, as outlined in the Processing Strategies section.
Consuming Events¶
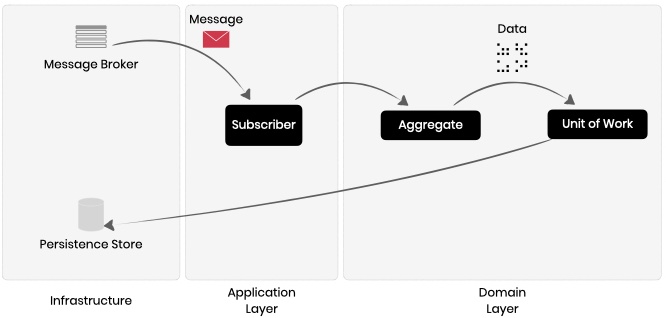
Subscribers live on the other side of event publishing. They are domain elements that subscribe to specific domain events and are notified by the domain on event bubble-up.
Subscribers can:
Help propagate a change to the rest of the system - across multiple aggregates - and eventually, make the state consistent.
Run secondary stuff, like sending emails, generating query models, populating reports, or updating cache, in the background, making the transaction itself performance-optimized.
A Subscriber can be defined and registered with the help of @domain.subscriber decorator:
@domain.subscriber(event='OrderCancelled')
class UpdateInventory:
"""Update Stock Inventory and replenish order items"""
def __call__(self, event: Dict) -> None:
stock_repo = current_domain.repository_for(Stock)
for item in event['order_items']:
stock = stock_repo.get(item['sku'])
stock.add_quantity(item['qty'])
stock_repo.add(stock)
Just like user-application-services and command-handlers, Subscribers should adhere to the rule of thumb of not modifying more than one aggregate instance in a transaction.
Processing Strategies¶
Protean provides fine-grained control on how exactly you want domain events to be processed. These strategies, listed in the order of their complexity below, translate to increased robustness on the event processing side. These performance optimizations and processing stability come in handy at any scale but are imperative at a larger scale.
Depending on your application’s lifecycle and your preferences, one or more of these strategies may make sense. But you can choose to start with the most robust option, DB_SUPPORTED_WITH_JOBS, with minimal performance penalties.
Event processing strategy for your domain is set in the config attribute EVENT_STRATEGY.
- INLINE¶
This is the default and most basic option. In this mode, Protean consumes and processes events inline as they are generated. Events are not persisted and are processed in an in-memory queue.
There is no persistence store involved in this mode, and events are not stored. If events are lost in transit for some reason, like technical faults, they are lost forever.
This mode is best suited for testing purposes. Events raised in tests are processed immediately so tests can include assertions for side-effects of events.
If you are processing events from within a single domain (if your application is a monolith, for example), you can simply use the built-in
InlineBrokeras the message broker. If you want to exchange messages with other domains, you can use one of the other message brokers, likeRedisBroker.config.py:... EVENT_STRATEGY = "INLINE" ...
- DB_SUPPORTED¶
The
DB_SUPPORTEDstrategy persists Events into the same persistence store in the same transaction along with the actual change. This guarantees data consistency and ensures events are never published without system changes.This mode also performs better than
INLINEmode because events are dispatched and processed in background threads. One background process monitors theEventLogtable and dispatches the latest events to the message broker. Another gathers new events from the message broker and processes them in a thread pool.Depending on the persistence store in use, you may need to manually run migration scripts to create the database structure. Consult
EventLogfor available options.Note that this mode needs the
Serverto be started as a separate process. If your application already runs within a server (if you have an API gateway, for example), you can run the server as part of the same process. Check user/server for a detailed discussion.config.py:... EVENT_STRATEGY = "DB_SUPPORTED" ...
- DB_SUPPORTED_WITH_JOBS¶
This is the most robust mode of all. In this mode, Protean routes all events through the data store and tracks each subscriber’s processing as separate records. This allows you to monitor errors at the level of each subscriber process and run automatic recovery tasks, like retrying jobs, generating alerts, and running failed processes manually.
This mode needs the
Jobdata structure to be created along withEventLog.config.py:... EVENT_STRATEGY = "DB_SUPPORTED_WITH_JOBS" ...
Best Practices¶
Your Event’s name should preferably be in the past sense. Ex. RoleAdded, UserProvisioned, etc. They are representing facts that have already happened outside the system.
Event objects are immutable in nature, so ensure you are passing all event data while creating a new event object.
Events are simple data containers, so they should preferably have no methods. In the rare case that an event contains methods, they should be side-effect-free and return new event instances.
Subscribers should never be constructed or invoked directly. The purpose of the message transport layer is to publish an event for system-wide consumption. So manually initializing or calling a subscriber method defeats the purpose.
Events should enclose all the necessary information from the originating aggregate, including its unique identity. Typically, a subscriber should not have to contact the originating aggregate bounded context again for additional information because the sender’s state could have changed by that time.
